
About Sayna
Sayna: Unified Voice & Messaging Layer for AI Agents
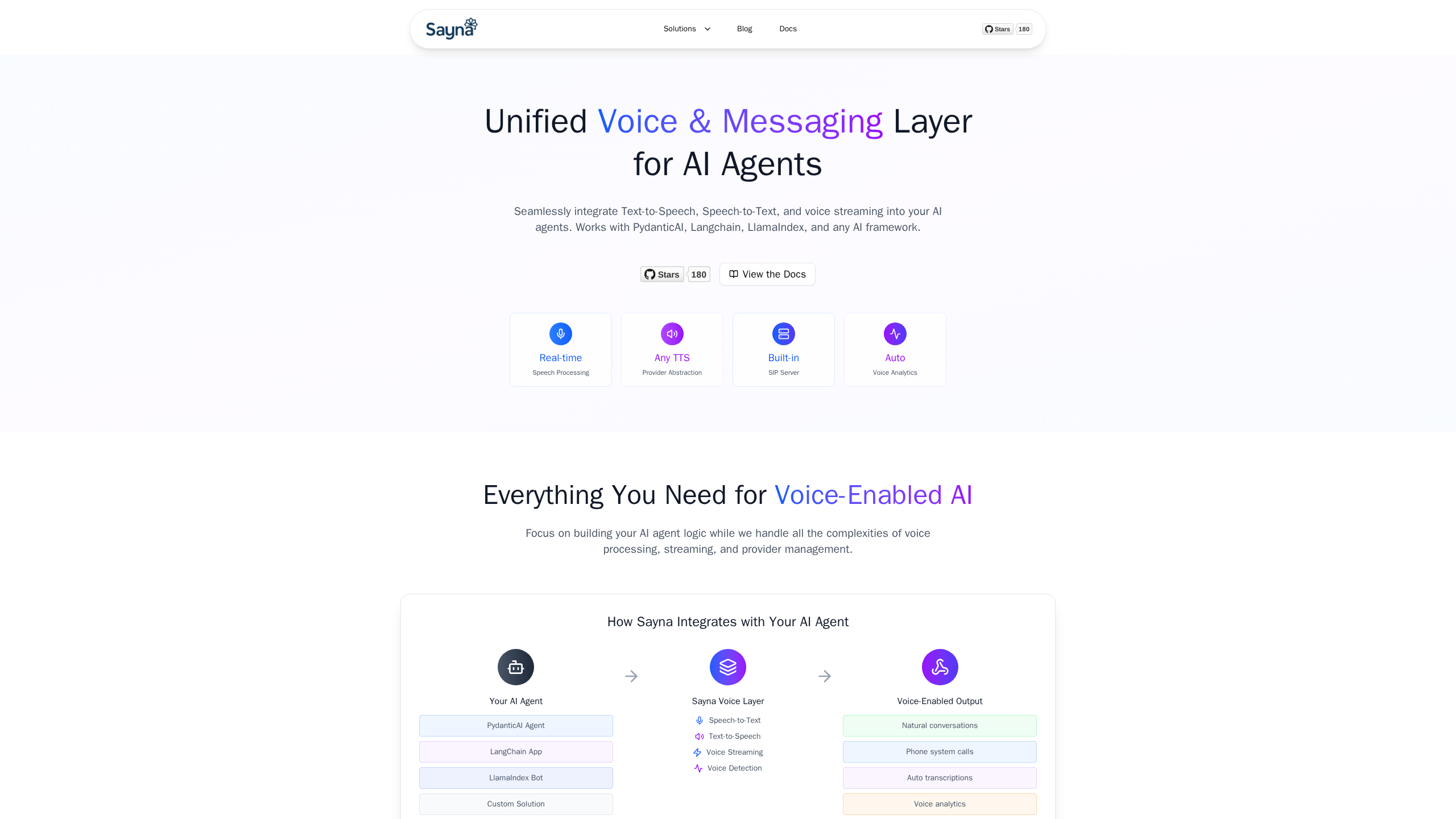
Sayna is a unified voice and messaging layer designed to seamlessly integrate Text-to-Speech, Speech-to-Text, and voice streaming into AI agents. It allows developers to focus on building AI agent logic while the platform handles the complexities of voice processing, streaming, and provider management.
Key Features
- Text-to-Speech (TTS) Abstraction: Offers provider abstraction for TTS services with seamless switching, a unified API, and real-time synthesis to prevent vendor lock-in.
- Speech-to-Text (STT): Provides a unified STT interface for real-time transcription and language detection across different speech recognition providers.
- Voice Streaming: Handles voice audio streaming with optimized low latency, audio optimization, and buffer management.
- Voice Activity Detection (VAD): Utilizes advanced VAD algorithms for smart detection, noise filtering, and managing natural conversation flows.
- Built-in SIP Server & Analytics: Includes a built-in SIP server and automatic voice analytics capabilities.
- Universal Compatibility: Works with existing AI frameworks like PydanticAI, LangChain, and LlamaIndex, and supports languages including Python, JavaScript, TypeScript, Go, and Rust.
Use Cases
- Natural Conversations: Enabling voice-enabled output for interactive AI agents.
- Phone System Calls: Integrating AI agents directly into telephony systems.
- Auto Transcriptions: Generating real-time text from spoken audio.
Getting Started
Website: https://sayna.ai/
Sayna provides an enterprise-ready, developer-first platform to add voice capabilities to existing AI agents with minimal code changes.

Tigran Bayburtsyan
Founder at Sayna.ai