
Real-time translation always looks cool in a demo, then the real world shows up.
People interrupt each other. Accents vary. Background noise creeps in. The model needs to understand what was said, translate it, and respond fast enough that the conversation does not feel broken. For voice AI builders, that is where translation stops being a “nice feature” and becomes a serious product challenge.
That is the problem Gradium is going after with the launch of Gradium Translate, a new real-time translation system built around two models: stt-translate and s2s-translate.
stt-translate turns speech in one language directly into translated text in another. s2s-translate takes that further, turning spoken input into spoken output in another language, with control over the target voice.
For anyone building multilingual voice agents, live interpretation tools, dubbing workflows, or real-time customer support, this is the interesting bit: Gradium is not treating translation as a bolt-on feature. It is building it as part of the live speech pipeline.
What’s new
Gradium is launching two models for real-time speech translation.
The first is stt-translate, a speech-to-text translation model that collapses transcription and translation into one step. Instead of sending audio through a speech-to-text model, then passing the transcript into a separate translation system, stt-translate translates directly from speech into text.
The second is s2s-translate, a speech-to-speech translation model that builds on stt-translate and pairs it with Gradium’s text-to-speech models. Audio goes in, translated speech comes out, and developers also receive the translated transcript as the system produces it.
The current supported languages are English, French, German, Spanish, and Portuguese. Since each language can map to any other language in that group, Gradium supports 20 translation directions at launch.
You can try the live experience on the Gradium Translate page, or explore implementation details in the Gradium API docs.
The hard part
The hard part with real-time translation is not only getting the words right.
It is getting the words right while keeping the conversation alive.
A classic speech-to-speech translation stack usually runs through three stages: speech-to-text, text-to-text translation, and text-to-speech. Each stage adds time. Each stage creates another handoff. And in voice products, even small delays can make the experience feel awkward.
Gradium’s approach reduces that chain.
With stt-translate, transcription and translation happen in a single pass. Then s2s-translate pairs the translated text with a Gradium TTS model to produce spoken output. That means developers do not have to stitch together separate STT, translation, and TTS systems themselves.
Less plumbing. Fewer handoffs. A cleaner path from “someone said something” to “someone hears the answer in another language.”
That matters a lot when you are building real-time systems.
Where it shows up
This kind of workflow can show up anywhere voice products need to cross language boundaries.
For voice agents, it could help teams build multilingual assistants without maintaining a messy translation pipeline behind the scenes.
For customer support and contact centers, it could make live multilingual conversations easier to support across regions.
For dubbing and localization, the voice layer becomes especially important because translated speech is not just about the words. It is also about how the speaker sounds.
For education, travel, accessibility, sales, and enterprise workflows, the same idea applies: people do not want slow, robotic translation. They want speech that feels immediate, understandable, and natural enough to keep the interaction moving.
This is also why real-time translation is becoming a recurring theme across the broader voice AI ecosystem. Voice AI Space has already covered related work in areas like real-time translation and TTS, and Gradium’s launch adds another strong signal that multilingual voice is becoming a production problem, not just a research demo.
Voice control is part of the product
One of the more useful parts of s2s-translate is control over the output voice.
Developers choose the target voice using a required voice_id. That voice can come from Gradium’s catalogue, or it can be a cloned voice.
That opens up more interesting product possibilities. A speaker can be translated into another language while keeping a voice identity that fits the product, brand, or use case.
For builders, that matters because voice AI is not only judged by accuracy. It is judged by timing, tone, continuity, and whether the final interaction feels believable.
If the translation is correct but the voice feels disconnected, the experience still breaks.
Does it hold up?
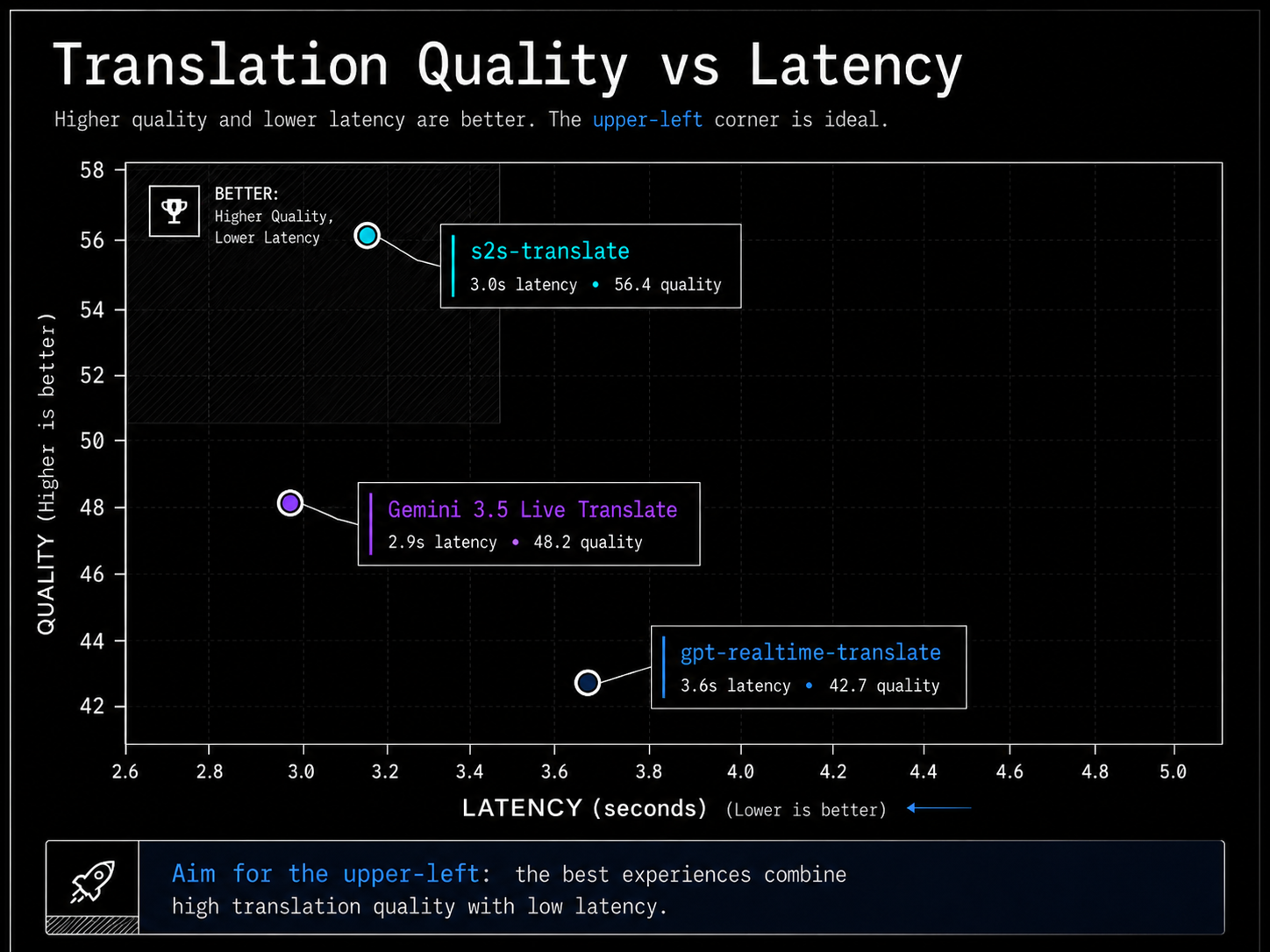
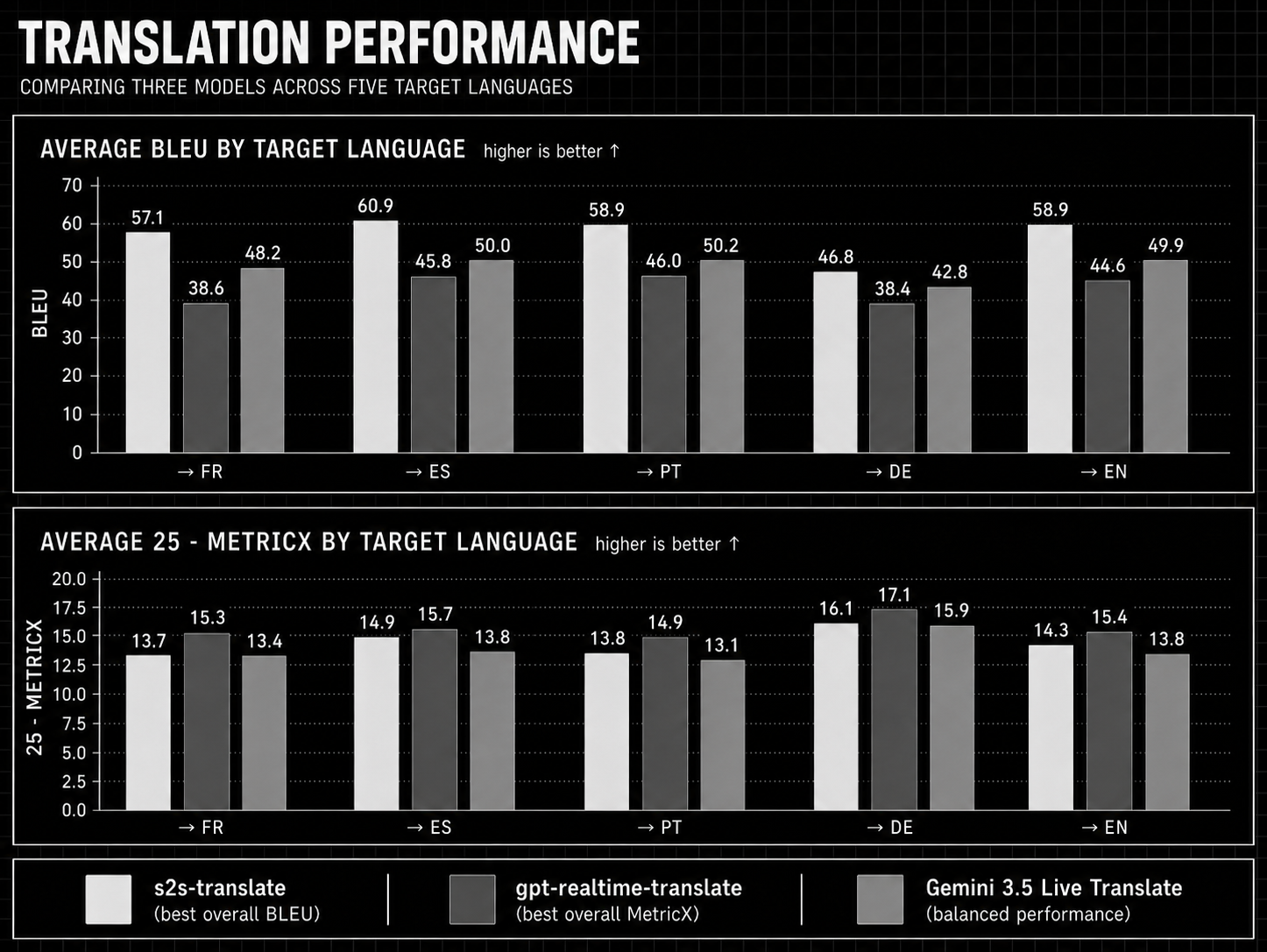
Gradium benchmarked stt-translate against gpt-realtime-translate and gemini-3.5-live-translate using conversational speech across everyday topics such as work, travel, holidays, and weather.
According to Gradium’s launch post, its model leads Gemini’s real-time translation system on both BLEU and MetricX. Compared with GPT’s real-time translation system, Gradium reports stronger BLEU performance and comparable MetricX performance.
On latency, Gradium reports an average of 3.0 seconds for s2s-translate, compared with 2.9 seconds for Gemini and 3.6 seconds for GPT.
That puts Gradium close to the fastest system in its comparison while making a strong company-reported claim on translation quality.
As always, the real test will be production audio: messy calls, different accents, background noise, overlapping speech, emotional conversations, and domain-specific vocabulary. Benchmarks are useful, but builders will still want to test this on the kind of audio their users actually produce.
Still, the direction is clear. Real-time speech translation is moving from “wow, that demo is neat” toward infrastructure that voice AI teams can actually build with.
Why we’re covering it
Multilingual voice is one of the next big pressure points for voice AI.
Voice agents are already moving into support, sales, healthcare, education, travel, entertainment, and enterprise workflows. But many systems still assume one main language, one clean audio stream, and one predictable user.
That is not how the real world sounds.
Gradium Translate is worth watching because it tackles a practical builder problem: how to make real-time translation faster, simpler to integrate, and more voice-native.
The most interesting part is the product shape. stt-translate reduces the translation chain. s2s-translate wraps it into a speech-to-speech workflow. Voice selection and cloning make the output more controllable. The result is a system that feels designed for real voice products, not just standalone translation demos.
If you are building multilingual agents, live interpretation tools, localization workflows, or voice-first products for global users, this launch belongs on your radar.
Read the full launch announcement from Gradium: Launching Gradium Translate.
Published in partnership with Gradium.


