
Gradium
Audio language models delivering real-time text-to-speech, speech-to-text, and voice cloning.
Perks
3 free months of S plan ($129 value)
1) Sign up using the link: gradium.ai
2) Select the S plan on the subscription page
3) Add your code at checkout: TBOT4FRIENDS
4) Start building with 3 free months of the S plan
Note: Valid until August 31st 2026. For first-time subscriptions only.
Startup Program
Gradium provides early-stage voice startups with over $2,000 in free API credits and direct engineering support. Grant recipients receive six months of full access to the M plan, providing up to 1,200 hours of text-to-speech or 4,998 hours of speech-to-text. Designed to eliminate prohibitive per-minute infrastructure costs, the program includes technical integration assistance for ultra-low latency voice models and early access to upcoming research previews.
Apply here



About Gradium
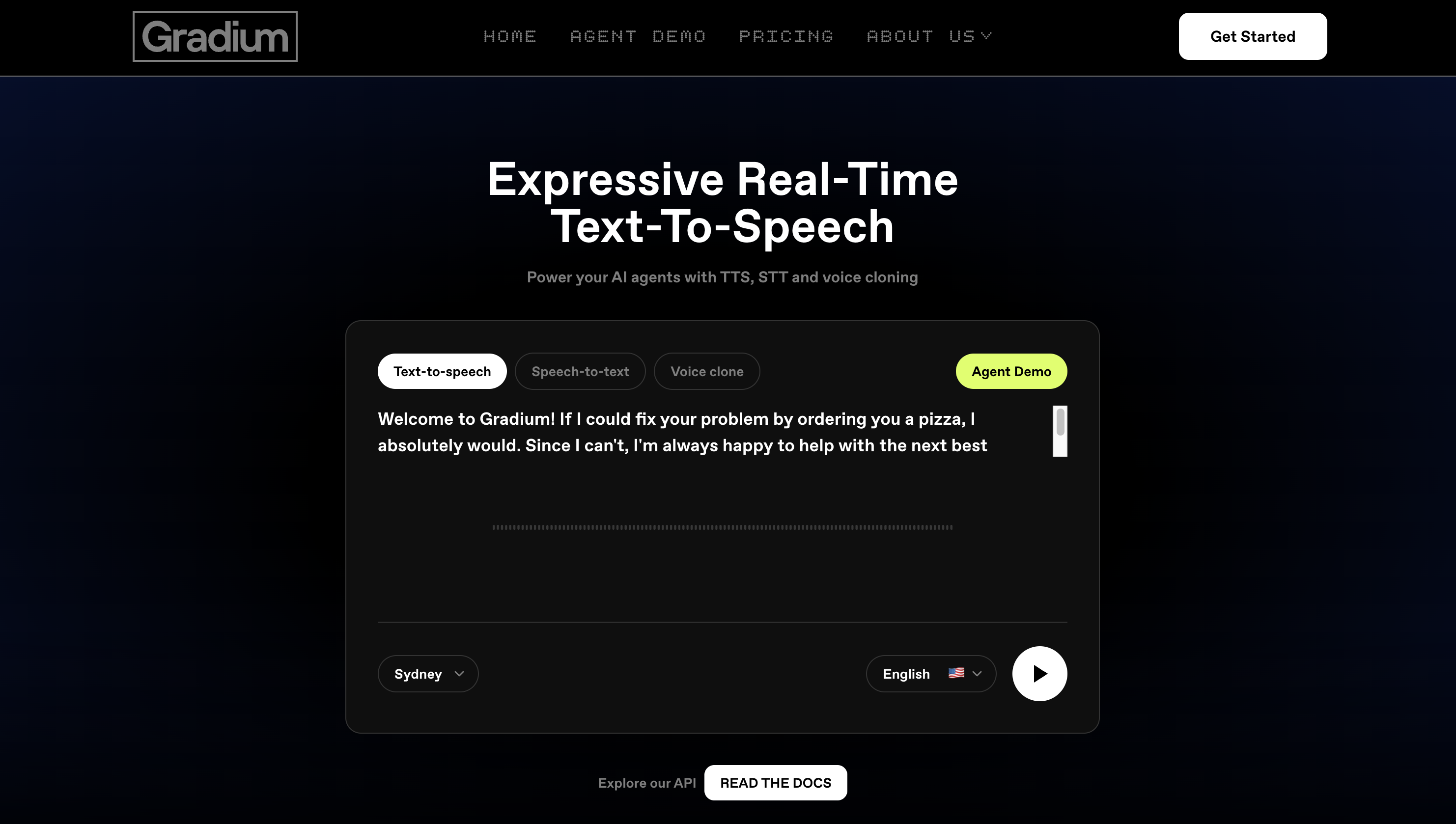
Gradium: Expressive Real-Time Text-To-Speech
Gradium develops audio language models designed to deliver natural, expressive, and ultra-low latency voice interactions at scale. The platform provides a full suite of voice AI models, including text-to-speech, speech-to-text, and voice cloning, to power AI agents and perform various voice tasks.
Key Features
Text-to-Speech (TTS): Offers seamless real-time streaming with natural, expressive speech, mastering complex pronunciations and providing high-precision word-level timestamps for perfect text-audio synchronization.
Speech-to-Text (STT): Delivers high accuracy with controllable latency, robust performance in noisy environments, and semantic voice activity detection for smart turn-taking.
Voice Cloning: Enables instant voice cloning from just 10 seconds of audio, alongside Pro Voice Clones for fine-tuned models with high speaker similarity.
Native Multilingual Fluency: Supports English, French, Spanish, German, and Portuguese with consistent pronunciation, prosody, and seamless mid-sentence code-switching without latency.
Developer Infrastructure: Features WebSocket APIs designed for streaming, Python and Rust SDKs, and integrations with major agent frameworks like Livekit and Pipecat.
Security and Compliance: Provides private cloud options for on-premise deployments and enterprise plans featuring zero data retention.
Use Cases
Gradium is built to power AI agents and real-time applications where low latency is a strict requirement, enabling bidirectional, real-time communication and high-concurrency voice tasks.
Getting Started
Website: https://gradium.ai/
Gradium provides production-grade voice AI APIs that handle latency, naturalness, and scale, allowing developers to build responsive and expressive voice-enabled applications.